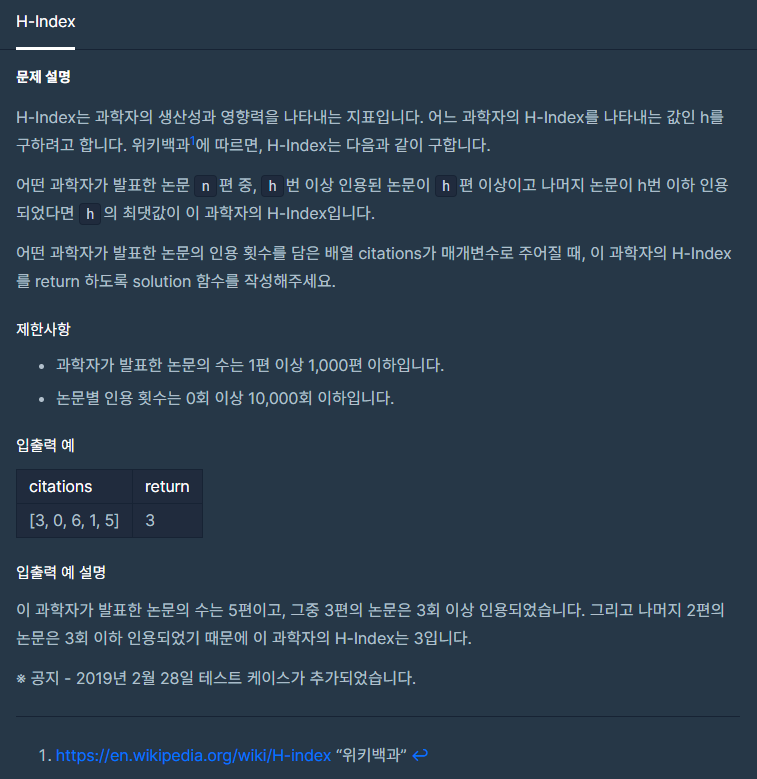
def solution(citations):
citations.sort()
LENGTH = len(citations)
MAX_NUM = 0
for i in range(max(citations)+1):
COUNT = 0
for j in range(LENGTH):
if i <= citations[j]:
COUNT += 1
if COUNT >= i:
MAX_NUM = i
return MAX_NUM하지만 의미를 파악하니까 쉽게 풀렸다. 우선 citations 배열을 순서대로 정렬하고, 그 배열의 가장 큰 숫자에 대하여 for문을 구현한다. 0부터 가장 큰 숫자까지 각각의 숫자 i에 대하여, 해당 i보다 크거나 같은 숫자가 있으면 COUNT에 추가한다. 이후, 그 i에 대하여, COUNT가 해당 i보다 크다면, MAX_NUM에 i를 지정한다.
이렇게 풀었더니 풀렸으나, 문제풀이 시간이 좀 길었다. 따라서 다른 사람은 어떻게 풀었는지 확인해보았다.
다른 사람의 풀이
프로그래머스에서 가져온 문제 풀이이다. 가장 많은 좋아요 수를 받은 문제는 아니지만, 가장 흥미롭게 푼 것 같아 들고 왔다.
def solution(citations):
citations.sort(reverse=True)
answer = max(map(min, enumerate(citations, start=1)))
return answer이 사람은 특이하게도, map(min, enumerate(citations, start=1))을 사용하여 풀었다. 이는 내가 만든 citations 배열을 예시로 들도록 하겠다:
citations = [[9, 9, 8, 8, 7, 7, 5, 5, 3, 3, 3, 3, 2, 0]
# 이미 정렬됐다고 가정했다.
>>> for i in enumerate(citations, start=1):
print(i)
(1, 9)
(2, 9)
(3, 8)
(4, 8)
(5, 7)
(6, 7)
(7, 5)
(8, 5)
(9, 4)
(10, 3)
(11, 3)
(12, 3)
(13, 3)
(14, 2)
(15, 0)
# 해당 숫자들보다 큰 숫자가 몇개인지 0번째 index에서 나타나는 것을 볼 수 있다. 따라서 이 문제의 'h번 이상 인용된 논문이 h편 이상이다'를 만족하기 위해서는, 각 tuple의 가장 작은 숫자 중, 가장 큰 숫자를 뽑아내면 될 것이다. 이 문제를 푼 사람은 여기서 max(map(min, enumerate(citations, start=1)))을 사용하여 풀었다. (참고로, tuple의 가장 작은 숫자가 0번째 index인 가장 큰 숫자 이후의 tuple들에서는 1번째 index가 가장 작은 숫자로 나온다.)
너무나도 신기하게 풀었는데다가, 너무나도 쉽게 풀어서 당황했다. 생각해보면 이 숫자들을 (x,y) 좌표에 투영했을 때(x=논문 개수, y=인용개수), y=x 바로 왼쪽에 가깝게 있는 점이 우리가 찾고자 하는 H-Index가 될 것임을 알아차리면 됐다.
'알고리즘 테스트 > 프로그래머스 문제풀이 및 해설' 카테고리의 다른 글
| <프로그래머스 문제풀이: 올바른 괄호> Level 2 - 파이썬 (0) | 2020.12.14 |
|---|---|
| <프로그래머스 문제풀이: [해시] 전화번호 목록> Level 2 - 파이썬 (0) | 2020.12.13 |
| <프로그래머스 문제풀이: [완전탐색] 소수 찾기> Level 2 - 파이썬 (0) | 2020.12.11 |
| <프로그래머스 문제풀이: [스택/큐] 주식가격> Level 2 - 파이썬 (0) | 2020.12.10 |
| <프로그래머스 문제풀이: [스택/큐] 프린터> Level 2 - 파이썬 (0) | 2020.12.09 |
